H Анализ дружеских связей VK с помощью Python. Часть первая. Друзья друзей в черновиках
В предыдущей статье мы на основе общих друзей ВКонтакте строили граф, а сегодня поговорим о том, как получить список друзей, друзей друзей и так далее. Предполагается, что вы уже прочли предыдущую статью, и я не буду описывать все заново. Начнем с того, что просто скачать все id пользователей достаточно легко, список валидных id можно найти в Каталоге пользователей Вконтакте. Наша же задача — получить список друзей выбранного нами id пользователя, их друзей и рекурсивно сколь угодно глубоко, в зависимости от указанной глубины.
Код, опубликованный в статье, будет меняться с течением времени, поэтому более свежую версию можно найти в том же проекте на Github.
Как будем реализовывать:
- Задаем нужную нам глубину
- Отправляем исходные данные либо те id, которые надо исследовать на данной глубине
- Получаем ответ
Что будем использовать:
- Python 3.4
- Хранимые процедуры в ВКонтакте
Задаем нужную нам глубину
Что нам потребуется в начале — это указать глубину (deep
), с которой мы хотим работать. Сделать можно это сразу в
main.py
: print(a.deep_friends(2)) # такая строчка там уже есть
deep
равное 1 — это наши друзья, 2 — это друзья наших друзей и так далее. В итоге мы получим словарь, ключами которого будут id пользователей, а значениями — их список друзей.
Не спешите выставлять большие значения глубины. При 14 моих исходных друзьях и глубине равной 2, количество ключей в словаре составило 2427, а при глубине равной 3, у меня не хватило терпения дождаться завершения работы скрипта, на тот момент словарь насчитывал 223.908 ключей. По этой причине мы не будем визуализировать такой огромный граф, ведь вершинами будут ключи, а ребрами — значения.
Отправление данных
Добиться нужного нам результата поможет уже известный метод friends.get, который будет расположен в хранимой процедуре, имеющей следующий вид: var targets = Args.targets; var all_friends = {}; var req; var parametr = «»; var start = 0; // из строки с целями вынимаем каждую цель while(start Напоминаю, что хранимую процедуру можно создать в настройках приложения, пишется она на VkScript
, как и
execute
, документацию можно прочесть здесь и здесь.
Теперь о том, как она работает. Мы принимаем строку из 25 id, разделенных запятыми, вынимаем по одному id, делаем запрос к friends.get
, а нужная нам информация будет приходить в словаре, где ключи — это id, а значения — список друзей данного id.
При первом запуске мы отправим хранимой процедуре список друзей текущего пользователя, id которого указан в настройках. Список будет разбит на несколько частей (N/25 — это и число запросов), связано это с ограничением количества обращений к API ВКонтакте.
Получение ответа
Всю полученную информацию мы сохраняем в словаре, например: {1:(0, 2, 3, 4), 2: (0, 1, 3, 4), 3: (0, 1, 2)} Ключи 1, 2 и 3 были получены при глубине равной 1. Предположим, что это и были все друзья указанного пользователя (0).
Если глубина больше 1, то далее воспользуемся разностью множеств, первое из которых — значения словаря, а второе — его ключи. Таким образом, мы получим те id (в данном случае 0 и 4), которых нет в ключах, разобьем их опять на 25 частей и отправим хранимой процедуре.
Тогда в нашем словаре появятся 2 новых ключа:
{1:(0, 2, 3, 4), 2: (0, 1, 3, 4), 3: (0, 1, 2), 0: (1, 2, 3), 4:(1, 2, ….)} Сам же метод
deep_friends()
выглядит следующим образом: def deep_friends(self, deep): result = {} def fill_result(friends): for i in VkFriends.parts(friends): r = requests.get(self.request_url(‘execute.deepFriends’, ‘targets=%s’ % VkFriends.make_targets(i))).json()[‘response’] for x, id in enumerate(i): result[id] = tuple(r[x][«items»]) if r[x] else None for i in range(deep): if result: # те айди, которых нет в ключах + не берем id:None fill_result(list(set() — set(result.keys()))) else: fill_result(requests.get(self.request_url(‘friends.get’, ‘user_id=%s’ % self.my_id)).json()[‘response’][«items»]) return result Конечно, это быстрее, чем кидать по одному id в
friends.get
без использования хранимой процедуры, но времени все равно занимает порядочно много.
В заключение
Если бы friends.get
был похож на
users.get
, а именно мог принимать в качестве параметра
user_ids
, то есть перечисленные через запятую id, для которых нужно вернуть список друзей, а не по одному id, то код был бы намного проще, да и количество запросов было в разы меньше.
Данные мы собрали, сегодня на этом все. Далее мы будем с этими данными играться.
Узнать возраст пользователя VK или о чём ещё может рассказать социальный граф
«Скажи мне кто твой друг и я скажу, кто ты.» Еврипид 480—406 до н. э.
Долгое время я смотрел на API VK как кот на стиральную машину — меня гипнотизировала возможность провести какое-нибудь исследование в одной из крупнейших социальных сетей, которая проникла во многие сферы нашей жизни. И вот однажды родился вопрос, а можно ли по кругу общения пользователя социальной сети определить его возраст?

Для желающих узнать скрытый возраст и раньше был небольшой хак. Надо лишь воспользоваться поиском по людям, указать узкие параметры, чтобы искомый профиль попадал в выдачу, а затем бинарным поиском определить возрастной диапазон. Или окажется, что в контактной информации вдруг указан год окончания школы. И никаких скриптов писать не надо. Но скрытый возраст и косвенная информация могут быть искажены, а главное статья всё-таки не о том, как добыть побольше персональной информации. В статье предлагается проанализировать один из аспектов социального графа.
Одно из первых, что приходит на ум при рассмотрении связей профиля: давайте посмотрим возраст одноклассников и одногруппников, в подавляющем большинстве у данного пользователя будет возраст +- 1 год. За это спасибо всеобщему среднему образованию. Есть только один нюанс: выявить одноклассников. Чем больше проходит времени с выпускного, тем в более разношёрстных по возрасту кругах мы начинаем вращаться. Школьные друзья словно оказываются в прошлой жизни, и вот их уже почти незаметно среди большого количества новых знакомых. Можно ли для профилей людей зрелого возраста как-то понять в какой поток они учились и, следовательно, примерный возраст?
Итак, давайте рассмотрим задачу определения возраста пользователя как определение подмножества одноклассников и одногруппников. То есть мы взяли за допущение, что у него в друзьях есть некоторое количество одноклассников, возраст которых примерно соответствует возрасту профиля. Конечно же бывают исключения, но они редки. Человек ходит в школу от звонка до звонка 10 лет, за такой срок успевают установиться множество перекрёстных социальных связей. Короче говоря, все друг друга знают, при этом разброс возраста в этом социальном клубке минимален. В дальнейшем, когда человек вливается в другие коллективы, как правило, разброс возраста в них значителен, будь это работа, спортивная активность или клуб по интересам. Попробуем, опираясь на такое различие, выявить нужные социальные группы.
Давайте для наглядности рассмотрим один из профилей ВК с большим количеством друзей. Получим список друзей пользователя с помощью запроса friends.get. Рассмотрим профили только с указанным возрастом и расположим их на временной шкале в виде гистограммы по годам. Есть небольшой нюанс с тем как разбивать множество друзей на годовые интервалы. Мы ведь хотим добиться, чтобы одноклассники вошли в один интервал, а не размазались по двум соседним. Опытным путём было установлено, что разбивать год лучше всего осенью, причём чтобы пользователи с датами рождения в жёлтое время года вошли сразу в два смежных интервала. То есть получаются 15 месячные интервалы с сентября по ноябрь с шагом 12 месяцев.
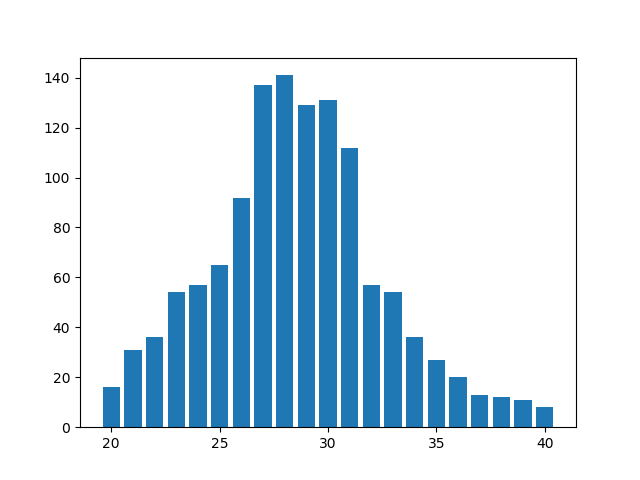
oX — возраст пользователей, оY — количество пользователей, попавших в заданный интервал.
Мы наблюдаем пятилетнее плато с максимальным годовым количеством друзей. Совсем не очевидно найти группу одногодок среди этого 5 летнего отрезка. По правде говоря, такая картина нетипична. Чаще год рождения одноклассников/одногруппников значительно выделяется среди других по большему количеству друзей. Но давайте в сложном случае для каждого пользователя найдём отношение дружеских связей внутри годовой группы к количеству связей с другими друзьями изначального пользователя, для кого мы определяем возраст; далее усредним этот показатель по каждому году. Назовём это нормированный коэффициент связности.
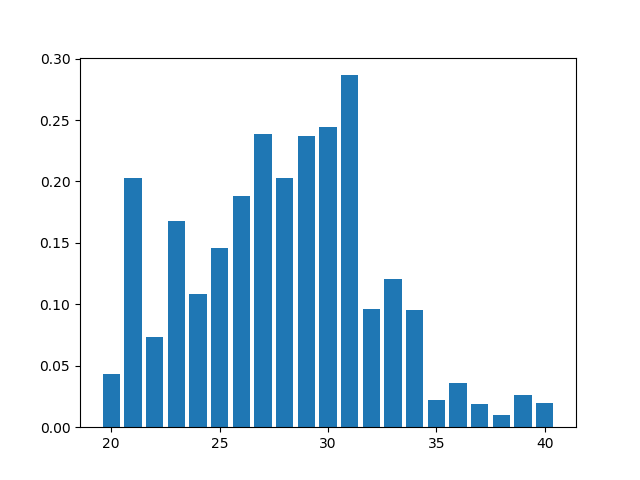
oX — возраст пользователей, оY — нормированный коэффициент связности для заданного интервала.
Картина изменилась, и в лидерах имеется единственный год. В нём большую долю имеет коллектив с однородным возрастом, следовательно имеем право ожидать, что раз пользователь является его частью, то имеет схожий возраст. А что, если человек в этом коллективе играет какую-то особенную роль, например, не одноклассник, а учитель? И вправду, для случая учителей/тренеров, могут существовать подгруппы с большой плотностью связей в узком возрастном промежутке. Частично такой случай удается обработать, если при выбирать группу не с самой высокой связностью, а с самым большим возрастом среди групп с достаточно большой связностью. Иными словами использовать логику, что человек на своем жизненном пути сначала должен побывать рядовым учеником, а уж потом играть выделенную роль в “коллективах с однородным возрастом”.
Более подробное описание и немного формул
Выразим численно обнаруженное на графике явление. Обозначим за
F0
— множество друзей пользователя, для которого вычисляется возраст.
Fi
— множество друзей произвольного профиля.
Fi,y
— множество друзей профиля, имеющих указанную дату рождения в годовом интервале y. Тогда
Сi,y
— связность профиля
i
в интервале
у
:
Сy
— ненормированный коэффициент связности в интервале у по всем профилям: И наконец искомый год рождения:
Ещё была идея рассматривать к какому типу относится та или иная связь. Если тип связи школьные или университетские друзья, то учитывать их с повышенным весом. А если тип коллеги, родственники и всё остальное, то не учитывать такие связи вообще. Однако, если использовать запросы, загружающие такую информацию, то время ожидания увеличивается раз в 5. К тому же, указывать тип связи — не популярная практика, поэтому было принято решение запрашивать такую информацию только для профилей с малым количеством друзей.
Из вышеобозначенного алгоритма вытекают естественные границы применимости подхода к определению возраста. Если пользователь не страдает ностальгией по школьным годам, и у него в друзьях отсутствуют его одноклассники/одногруппники, то надо использовать другой метод.
Как насчёт попробовать это безобразие в деле? Был реализован шуточный сервис в ВК группе «Гадалка возраста». Там дружелюбный бот погадает на возраст, если скинуть ему ссылку на незакрытый профиль ВК, используя вышеупомянутый алгоритм.
Как устроен сервис
Первым звеном в работе гадалки является механизм сообщений группы ВК. В настройках группы подключается callback API на собственный сервер. В качестве отправляемых типов событий надо выбрать “Входящее сообщение”. Таким способом сообщение группы превращается в запрос на нашем сервере. Если вы также как и я не дружите с фронтендом, то это супер вариант. Далее с сервера происходит обращение к VK API с запросами users.get для рассматриваемого профиля и friends.get для друзей профиля с известной датой рождения. Для их осуществления требуется access token приложения ВК. Я не использовал запросов, требующих подтверждения прав от пользователя, чтобы не грузить людей запросами на разрешение доступа. После того как произведён расчёт предполагаемого возраста, формируется ответ на запрос из группы, и пользователь гадалки видит ответ в диалогах. Дёшево и сердито.
Что касается улучшения самого алгоритма, ничего не мешает пойти ещё дальше, собрать обучающий датасет из профилей с указанным возрастом и натренировать регрессионную модель на основе, скажем, матрицы смежности возрастного графа среди друзей профиля. Уверен, при достаточно большой выборке результаты окажутся точнее эвристик. Как уже упомянул выше, мне было любопытно проверить принципиальную идею, поэтому развивать это направление не планирую.
В заключении хочется затронуть аспект этичности. На мой взгляд “Гадалка возраста” находится на границе частной жизни, но всё-таки не переступает её, потому что использует для анализа открытые данные. Собственно поэтому для пользователей со скрытым профилем сервис работать не будет.
Есть ощущение, что всякие «гадалки возраста», поисковики лайков, SearchFace – это лишь первые ласточки социально-прозрачного мира. В некоторой степени это можно назвать возвращением к истокам. Человек долгое время существовал в небольших социумах, где все друг у друга были на виду. Открытая репутация являлась неотъемлемой частью механизма социального регулирования. Да, новые инструменты постепенно позволят вновь сделать социальные взаимодействия человека как на ладони, только теперь уже на глобальном уровне. Да, как и любой инструмент, это можно использовать во вред. Нужно ли делать их доступными для каждого? Не знаю. Но я уверен, что если такие инструменты будут доступны лишь ограниченному кругу лиц, то баланс в сторону конструктивного использования точно не сместится.