Создание и наполнение онлайн-ресурса — это многоэтапный системный процесс. Контент фирменного сайта, интернет-магазина, лэндинга или портала должен постоянно обновляться с учетом целей и задач компании, изменений предпочтений целевой аудитории и алгоритмов поисковых систем. Но иногда старые тексты могут пригодиться, и тогда их можно найти на веб-архивах.

Что такое Web Archive?
Это бесплатный сервис, где собраны истории многих интернет ресурсов — их архивные копии. Причем речь идет не о скриншотах, а о полноценных страницах с изображениями, рабочими ссылками и стилевым оформлением.
Получение информации о том или ином домене предполагает не только интересное времяпровождение с отслеживанием эволюции веб-проекта, но еще и возможность:
- узнать тематику сайта — архив интернета демонстрирует содержимое, благодаря чему легко определить нишу проекта;
- посмотреть, как выглядел сайт раньше — это находка для охотников за б/у доменами;
- определить, регистрировался ли до этого анализируемый домен — полезный инструмент для тех, кому принципиальна «стерильность» домена или для того чтобы избежать санкций поисковиков;
- восстановить свой сайт, если вы почему-то не сделали резервное копирование.
- отыскать уникальный контент — трудоемкая задача, которая может подарить вам десятки бесплатных статей;
- увидеть удаленный текст из закладок — шансы найти нужную страницу достаточно высоки.
Возможности сервиса
Для вебмастера и SEO-специалиста бесплатные всемирные архивы открывают ряд полезных возможностей.
- Если планируется купить домен или интернет-проект, важно посмотреть историю сайта. В ней могут быть «криминальные» эпизоды. Например, распространение пиратских видеозаписей, продажа запрещенных товаров или адалт-контент. «Темное прошлое» может негативно сказаться на продвижении проекта в поисковых системах.
- Архив веб-страниц поможет при выборе дроп-домена. В сервисе можно посмотреть бесплатно, какой проект на нем располагался (коммерческий, информационный) и как он выглядел.
- Можно узнать историю конкурентов. Сравнивая архивы сайтов с их современной версией, легко понять, как менялась ниша, как трансформировались проекты.
- Есть возможность проследить и проанализировать изменения на собственном сайте и даже восстановить измененный по ошибке URL.
- С помощью дополнительных сервисов можно восстановить удаленный ресурс или отдельные страницы.
- А также найти контент по интересующей теме, которого уже нет в глобальной сети.
История создания архива интернета
Wayback Machine является одним из двух главных проектов archive.org. Этот некоммерческий сервис был создан в 1996 году Брюстером Кейлом. Машина времени сайтов имеет четкую цель: сбор и хранение копий ресурсов вместе со всем контентом для возможности свободного просмотра несуществующих или неподдерживающихся страниц в будущем. С 1999-го робот стал фиксировать еще и аудио, видео, иллюстрации, программное обеспечение.
База современного архива собиралась в течение 20 лет, у нее не существует аналогов. Статистика впечатляет: на сегодняшний день в сервисе находится 279 миллиардов страниц, 11 миллионов книг и статей, 100 тысяч программ и миллион картинок.
А знаете ли вы? Веб-архив сайтов часто имеет проблемы на законодательном уровне из-за нарушения авторских прав. По требованию правообладателей библиотека удаляет материалы из публичного доступа.
Кэш Яндекса, почему бы и нет
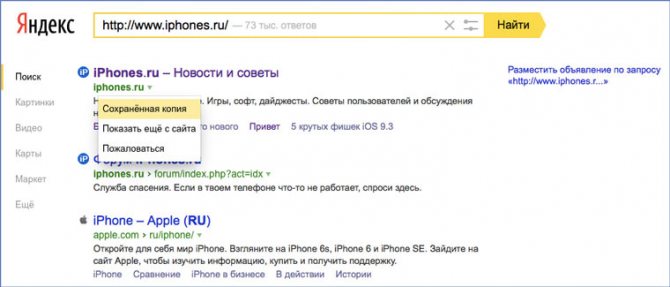
К сожалению, нет способа добрать до кэша Яндекса по прямой ссылке. Поэтому приходиться набирать адрес страницы в поисковой строке и из контекстного меню ссылки на результат выбирать пункт Сохраненная копия. Если результат поиска в кэше Google вас не устроил, то этот вариант обязательно стоит попробовать, так как версии страниц в кэше Яндекса могут отличаться.
Как пользоваться веб-архивом?
Сервис очень удобный в применении. Пошаговая инструкция такова:
- Зайдите на главную страницу платформы.
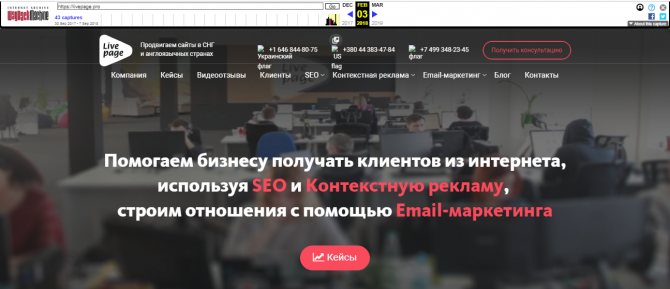
- Введите в поле название интересующего вас сайта и нажмите Enter (в нашем случае это ).

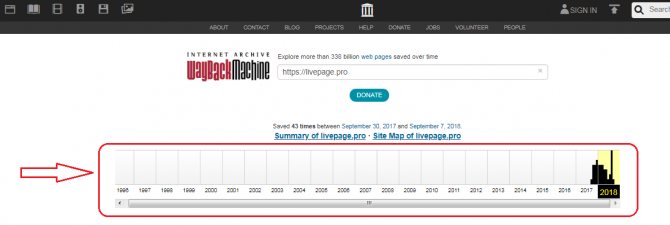
- Под указанным доменным именем демонстрируется основная информация: когда начинается история проекта, сколько слепков имеет сайт. В примере видно, что ресурс был впервые архивирован 30 сентября 2022 года, библиотека хранит его 43 архивные копии.
- Дальше мы обращаем внимание на календарь — голубым цветом в нем отмечены даты создания слепков.
Каждый из них доступен для просмотра: нужно лишь выбрать год, месяц и день сохранения. Мы хотим посмотреть, как выглядел сайт раньше: допустим, 3 февраля текущего года. Наводим курсор на голубой кружок и жмем на время сохранения. Проще не бывает! - При желании можно получить общие данные о web-проекте — надо нажать на кнопку Summary над хронологической таблицей и календарем или же ознакомиться с картой сайта (кнопка Site Map).
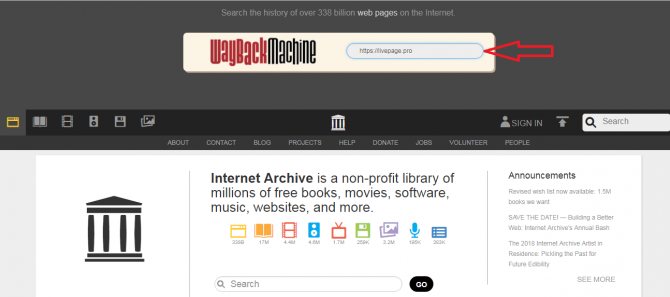

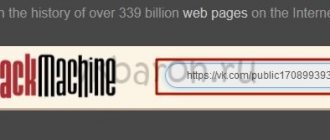
Алгоритм действий можно сократить. Для работы с сервисом напрямую, введите в строке своего браузера
https://web.archive.org/web/*/https://url.
В нашем случае это
https://web.archive.org/web/*/https://livepage.pro.
Как узнать историю домена?
В этом помогут специализированные сервисы. Вообще, полный их функционал обычно платный, но и бесплатных возможностей хватит, чтобы сделать выводы.
Сервис whois.domaintools.com
Переходим по этому адресу whois.domaintools.com/ и вводим в данное поле своё доменное имя:
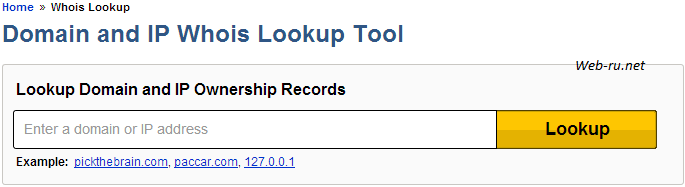
Сервис whois.domaintools.com
Ну а далее смотрим результаты.
Вот пример для купленного недавно (29 сентября 2013) домена без истории:
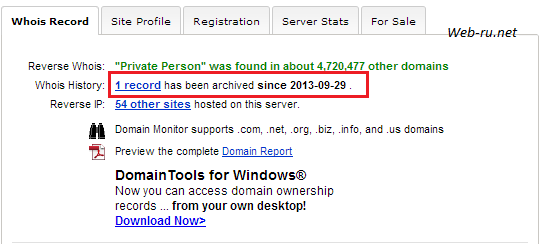
Данные от whois.domaintools.com
Что здесь видно:
- Whois History: сколько раз менялись Whois-записи (данные о владельце)
- Reverse IP: сколько имеется сайтов на том же IP, к которому прикреплён домен.
Так что если для вашего домена выводятся подобные данные, то с большой вероятностью только вы и были его владельцем.
Вот пример для совершенно «чистого домена» — который ни разу не покупался:
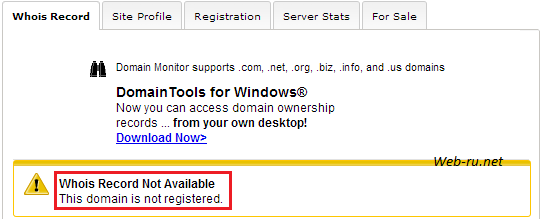
Абсолютно «чистый» (по данным whois.domaintools.com)
Если вам нужно доменное имя без истории — то такие и надо брать.
Также данный сервис выдаёт информацию о доменах, выставленных на продажу:
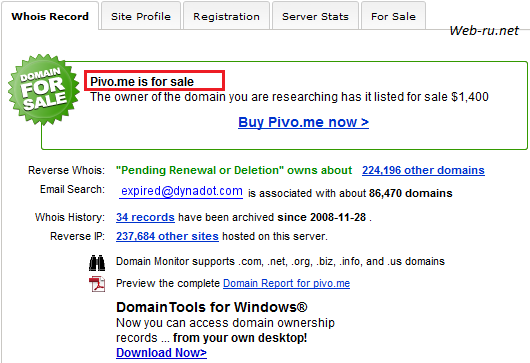
Домен pivo.me продаётся
Если желаете купить pivo.me, то можете кликнуть на «Buy Pivo.me now >» и приобрести его за 1400 USD.
Ну и домен с плохой историей — на примере web-ru.net:
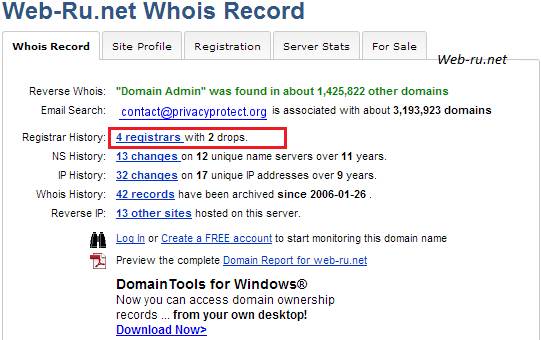
whois.domaintools.com — данные о web-ru.net
Главное, на что следует обратить внимание в таких случаях, это строка «Registrar History». На картинке выше видно, что доменное имя регистрировалось 4 раза, но 2 раза было «дропнуто» — т.е. через некоторое время бывшие владельцы не стали его продлевать (очевидно, были причины).
Таким образом, если нужен домен с хорошей историей — то желательно, чтобы «дропов» не было вообще.
Сервис от Reg.ru
Находится здесь https://www.reg.ru/whois/history/. Он платный, но является бесплатным для партнёров сервиса и только при проверке зоны .RU.
Уже не помню, как я стал партнёром Reg.ru. Возможно, чтобы стать им, вам следует зарегистрироваться по мой реф-ссылке, а возможно и нет.
Здесь выбираем тип запроса — «Запрос истории Whois» и жмём «Добавить в корзину»:
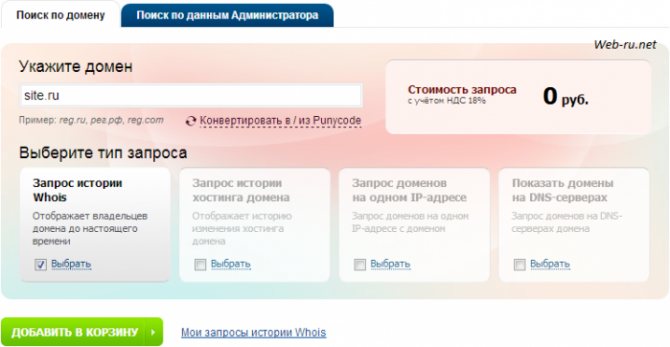
История домена в Reg.ru
На следующей странице подтверждаем заказ услуги:
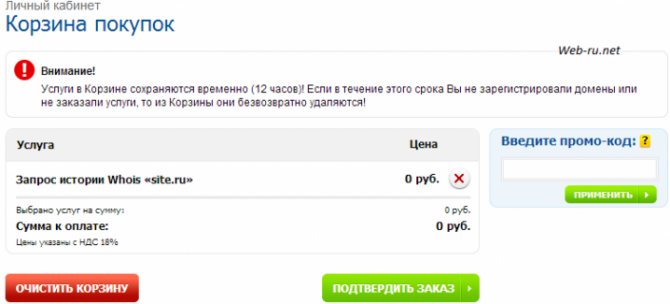
Подтверждение заказа в Reg.ru
Ну а на следующей щёлкаем «Посмотреть» (можно отправить результат на email):
Данные о домене в Reg.ru
Будет показа «миграция» доменного имени от одного хостинга к другому и смена владельцев. И всё это по датам.
Как восстановить сайт из веб-архива?
Плохая новость для тех, кто планирует просто найти архив сайта и скачать его привычным способом: страницы имеют вид статических html-файлов, к тому же их слишком много для того, чтобы заниматься этим вручную. Решить проблему можно при помощи специальных программ, к примеру, приложения на ruby. Необходимо лишь установить все на сервер и запустить восстановление страниц.
- Установите «Руби».
apt-get install ruby

- Добавьте саму программу, необходимую для работы.
gem install wayback_machine_downloader
- Запустите выкачивание сайта из web archive.
wayback_machine_downloader https://www.site.ru -timestamp 20131209110704
Для удобства можно указать отметку снапшота — утилита определит число страниц и выведет выкачиваемые файлы на консоль. После скачивания и сохранения мы получим набор статических данных.
- Разместите файлы в выбранной папке. Подойдет rsync:
rsync -avh./websites/www.site.com/ /var/www/site.com/
- Создайте конфигурацию в nginx и дождитесь обновления dns. На этом все!
Кэш браузера, когда ничего не помогает
Страницу целиком таким образом не посмотришь, но картинки и скрипты с некоторых сайтов определенное время хранятся на вашем компьютере. Их можно использовать для поиска информации. К примеру, по картинке из инструкции можно найти аналогичную на другом сайте. Кратко о подходе к просмотру файлов кэша в разных браузерах:
Safari
Ищем файлы в папке
Google Chrome
В адресной строке набираем chrome://cache
Opera
В адресной строке набираем opera://cache
Mozilla Firefox
Набираем в адресной строке about:cache и находим на ней путь к каталогу с файлами кеша.
Как восстановить сайт без бэкапа?
Вернуть ресурс из небытия можно даже без резервного копирования.
- Как уже говорилось раньше, можно восстановить сайт из веб-архива https://archive.org. Чтобы получить все страницы, введите в специальное поле имя ресурса с добавлением /* (*). Здесь же предусмотрена возможность фильтрации файлов по подстроке в URL. Для скачивания файлов подойдут многие программы, например, Teleport Pro.
- Страницы интернет-проектов часто хранятся в кэше поисковых систем. По причине того что у каждого поисковика свои параметры, для лучшего эффекта промониторьте не только Google и Яндекс, но и Bing, Rambler:
https://www.google.ru/advanced_search https://yandex.ru/search/advanced https://www.bing.com/ https://nova.rambler.ru/srch/advanced
Войдите в режим расширенного поиска и укажите имя сайта. Получив результаты, кликайте по ссылкам «cached» или «копия».
- Если вы отдаете полный RSS, тогда стоит проверить еще и ридеры, агрегаторы.
Учтите!
Нужный вам проект может и не входить в архив сайтов интернета. Если вы его не нашли в библиотеке — значит, правообладатель потребовал удаления копий или же ресурс закрыли в соответствии с законом о защите интеллектуальной собственности. Возможен и другой вариант: через файл robots.txt был банально внесен соответствующий запрет.
Как удалить копии страниц своего проекта?
Не всем и не всегда хочется выкладывать историю своей веб-площадки на всеобщее обозрение. Например, на сайте могла быть выложена ошибочная, некорректная или противозаконная информация. Даже если удалить страницу или файл, они сохранятся в библиотеке.
Архивом страниц могут заинтересоваться конкуренты и недоброжелатели. Поэтому многим хочется удалить копии веб-документов из сервиса.
Раньше вебмастера вписывали в robots.txt запрещающую директиву для ботов. Но сейчас это уже не работает.
Убрать страницы из библиотеки можно только через саппорт. Для этого нужно написать письмо на Писать нужно по-английски, с указанием реальных имени, фамилии, физического адреса. Чтобы подтвердить, что вы владелец ресурса, отправлять письмо лучшего с почтового ящика, указанного на сайте. Еще один способ подтвердить свои права — написать через регистратора домена или через хостинг. Иногда саппорт просит прислать копию паспорта.
Через поддержку можно навсегда запретить делать копии своего проекта.
Как найти уникальный контент из веб-архива для вашего сайта?
Статьи, расположенные на заброшенных ресурсах, обычно не представляют никакой ценности для их бывших владельцев. А ведь в мир иной ежедневно уходят десятки сайтов. И среди кучи хлама, выброшенного на помойку истории, можно найти настоящие самородки — приличные тексты, которые достанутся вам бесплатно.
Поисковики хорошо относятся к любому актуальному и уникальному контенту — можно не бояться попасть в их немилость только из-за того, что статьи взяты из веб-архива чужого сайта.
Итак, последовательность действий следующая:
- Найдите подходящие вам блоги. Для этого следует зайти на Reg.ru и скачать оттуда список недавно освободившихся доменов.
- Посетите архив интернета с целью поиска сохраненных копий.
- Проверьте понравившиеся тексты через антиплагиат (контент может быть уже скопирован на другие сайты).
- Опубликуйте уникальные статьи на своем ресурсе.
При разумном подходе такой способ пополнения сайта контентом можно поставить на поток. Поиски материалов на мертвых блогах оправданы экономией времени на написание текстов и денег, которые бы вам пришлось заплатить авторам.
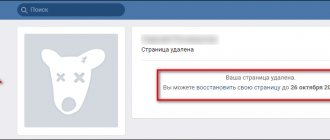
Как посмотреть, как раньше выглядела страница «ВКонтакте» через Internet Archive?
Этот способ отличается от вышеописанного тем, что в архиве нет никаких особых требований к тому, как именно должна выглядеть и быть настроенной страница, но при этом здесь есть не все профили, так как загружать в архив их нужно ручным способом. Для начала нужно перейти в сам архив по этой ссылке. Далее здесь в соответствующем поле нужно ввести непосредственно сам адрес к тому профилю, старую версию которого требуется посмотреть. Если поиск будет проведен успешно, то пользователь увидит специальную шкалу времени, а также календарь с разными датами обновлений сохраненных копий профиля. При этом нужно понимать, что непопулярные страницы реже сохраняются в этом архиве, либо не сохраняются здесь вовсе. На временной шкале здесь нужно просто переключаться между разными периодами активности. Далее в отобразившемся календаре следует выбрать требуемую дату, за которую нужно посмотреть копию страницы. Нажимать и смотреть можно только те даты, которые подсвечены в этом календаре. После наведения курсора мыши на нужную дату появятся также разные варианты с ссылками на время сохранения страницы. Здесь нужно просто выбрать правильное время, чтобы старая версия профиля открылась.
Как сделать так, чтобы сайт не попал в библиотеку веб-архива?
Если вы дорожите контентом и не хотите видеть свою онлайн-площадку в электронной библиотеке, пропишите запретную директиву в файле robots.txt:
User-agent: ia_archiver Disallow: /
User-agent: ia_archiver-web.archive.org Disallow: /
После изменения в настройках веб-сканер перестанет создавать архивные копии вашего сайта, к тому же удалит уже сделанные слепки. Однако учтите, что ваш запрет действует лишь до тех пор, пока доступен robots.txt — когда закончится срок регистрации доменного имени, машина времени сайтов станет демонстрировать статьи всем желающим.
Важно! Если вы, наоборот, желаете активно пользоваться веб-архивом, введите соответствующий запрос на главной странице сервиса. Просто укажите адрес проекта в разделе Save Page Now, после чего нажмите кнопку Save Page. Повторяйте процедуру после внесения любых правок.
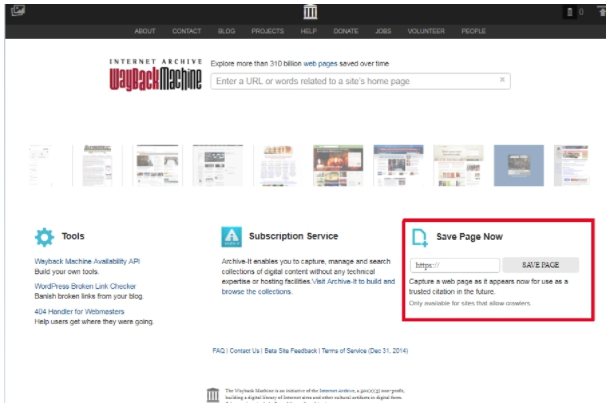
Как добавить страницу в сервис?
Боты обходят интернет по собственному графику. Не все проекты попадают в историю «Машины времени». Молодые площадки с небольшим трафиком редко оказываются в библиотеке. А если и попадают туда, то частота сканирований очень низкая — раз в несколько месяцев.
Сохранять копии сайта в WebArchive можно самостоятельно. Для этого нужно открыть сервис, найти поле «Сохранить страницу» и добавить туда URL. Снимки появятся в библиотеке через пару минут.
Эту операцию можно периодически повторять.
В будущем эти копии будут полезны, чтобы отслеживать изменения в дизайне, структуре, контенте. Если страницы будут по ошибке удалены, а бэкапы не делались или были утеряны, архивные снимки помогут восстановить документ.