Обновлено 3 января 2022 178 Автор: Дмитрий Петров
Здравствуйте, уважаемые читатели блога KtoNaNovenkogo.ru. Не так давно я писал про то, что такое народная энциклопедия Википедия, которая безусловно заслуживает всяких лестных эпитетов, несмотря на присущие ей небольшие недостатки и критику ее статей со стороны научного сообщества.
Сам факт того, что некоммерческий проект уже не одно десятилетие трудится на благо всего интернет сообщества, заслуживает огромного уважения. Но в сети есть еще подобный масштабный проект, который не получая с этого дохода выполняет очень важную роль — сохраняет архивы сайтов, видео, аудио и печатной продукции.

Я говорю, конечно же, про web.archive.org — глобальный проект с казалось бы невыполнимой миссией — создание архива всех сайтов, когда либо размещенных в интернете. Причем, сайты сохраняются не в виде скриншотов, а в виде полноценно работающих веб-страниц со всеми ссылками, картинками и стилевым оформлением (CSS). Причем, для каждого сайта за время его существования в сети в этом архиве может накопиться и по несколько сотен копий, датированных разными этапами жизни ресурса.
Зачем нужна информация об истории сайта в прошлом
Историю любого сайта можно посмотреть в интернете. Для этого достаточно, чтобы ресурс существовал хотя бы пару дней. Это может понадобиться в следующих случаях:
- Если необходимо купить домен, который уже был в использовании, и нужно посмотреть контент какой тематики был на нем размещен, не было ли огромного количества рекламы, исходящих ссылок и т.д.
- Нужен уникальный контент. Его можно скачать с существовавших когда-то ресурсов. Такое наполнение подойдет, например, для сайта-сателлита.
- Нужно восстановить сайт, когда нет его бэкапа.
- Нужно проанализировать конкурентов. Этот способ понадобится чтобы посмотреть историю изменений на их сайтах, какие ошибки они допускали или, наоборот, какие “фишки” стоит позаимствовать.
- Необходимо посмотреть страницу, если она теперь недоступна напрямую.
- Интересно , как выглядел ресурс 10-20 лет назад.
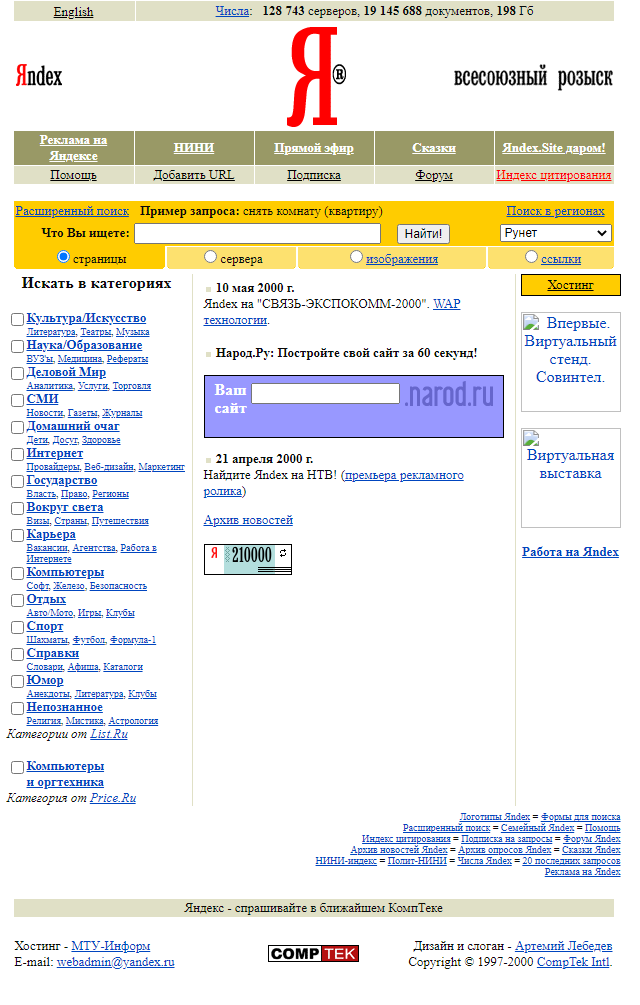
Ниже приведен пример того, как выглядела стартовая страница поисковой системы Яндекс в 2000 году:
Способ 1. Постраничное сохранение
Самый простой способ о котором все знают, даже если ни разу не пользовались. Эта возможность есть в любом браузере. Достаточно лишь нажать комбинацию клавиш «Ctrl»+«S», после чего в открывшемся окне отредактировать название сохраняемой страницы и указать папку, в которую ее следует поместить.
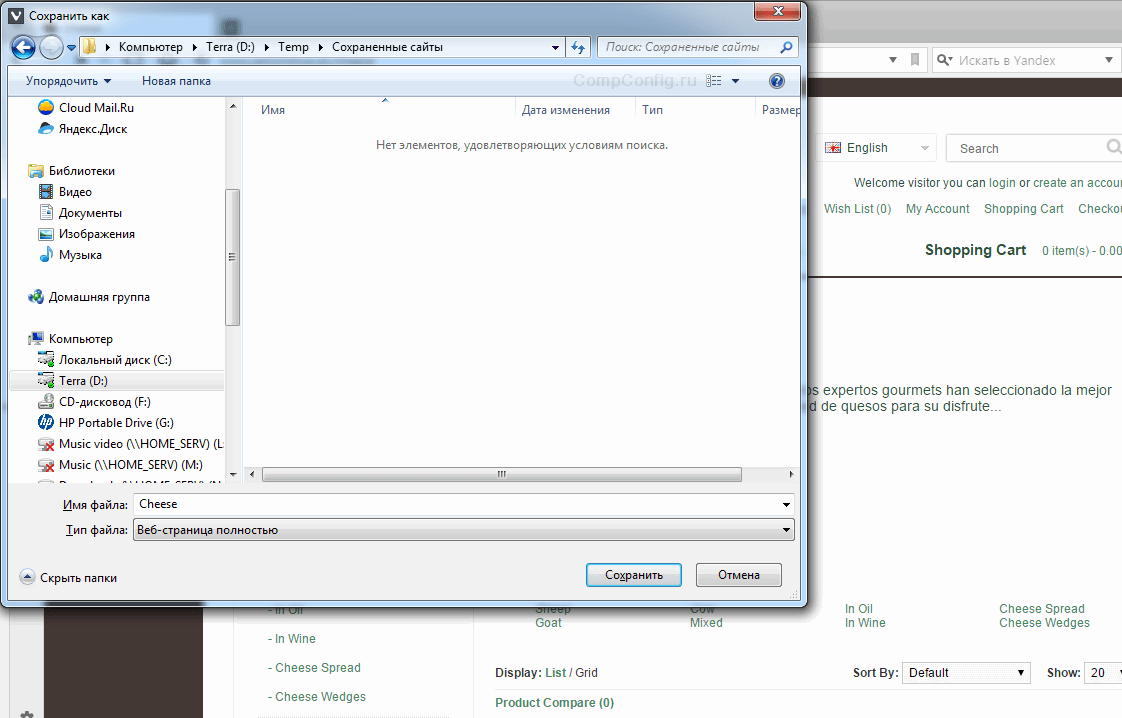
Казалось бы, куда проще. Вот только есть в этом способе один существенный недостаток. Мы скачали всего лишь одну страницу, а в интересующем нас сайте таких страниц может быть весьма большое количество.
Хорошо, если сайт маленький, или состоит всего из одной страницы, а если нет? Придется выполнять это действие для каждый из них. В общем, работа для усидчивых и целеустремленных, не знающих об одном из основных двигателей прогресса.
Как посмотреть сайт в прошлом
Есть несколько сервисов, в которых можно посмотреть, как менялось визуальное оформление страниц сайта, его структуру страниц и контент, положение в поисковой выдаче и какие изменения вносились в регистрационные данные за время существования ресурса.
Сервис Веб-архив
При его использовании сначала заходим на сайт https://web.archive.org/ и после вводим адрес страницы.

График ниже показывает количество сохранений: первое было в 1998 году.

Дни, в которые были сохранения, отмечены кружком. При клике на время во всплывающем окне, открывается сохраненная версия. Показано ниже:

Как выгрузить сайт из ВебАрхива, расскажем дальше.
Сервис Whois History
Для его использования заходим на сайт https://whoishistory.ru/ и вводим данные в поиске по доменам и IP, либо по домену:
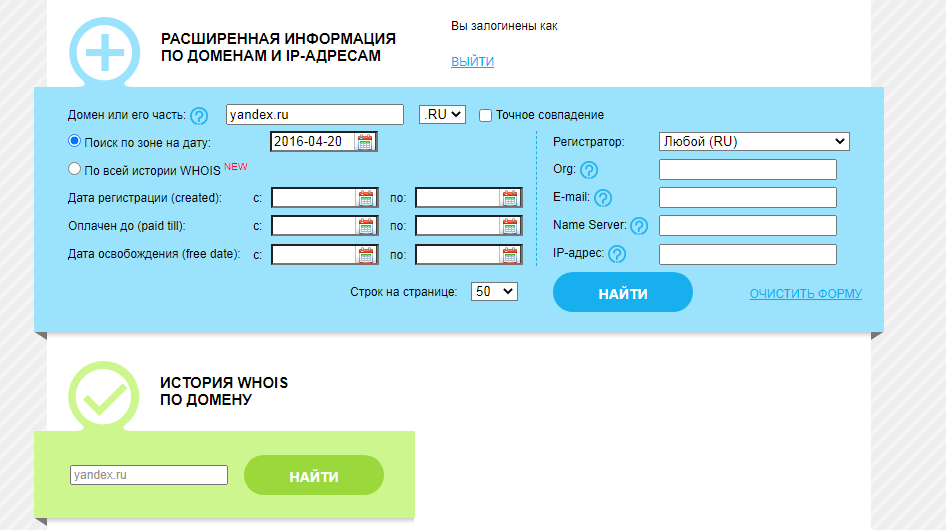
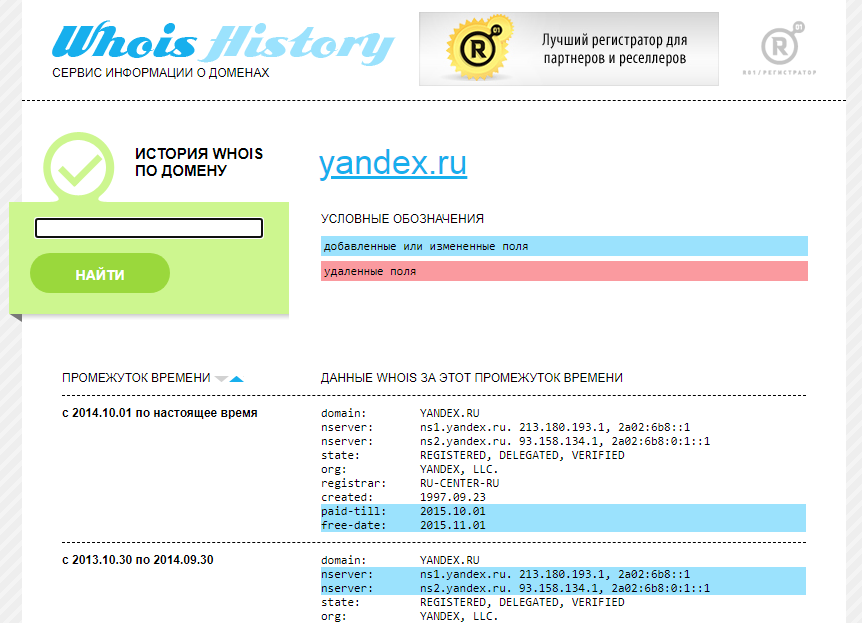
Сервис покажет информацию по данным Whois, где собраны сведения от всех регистраторов доменных имен. Посмотреть можно возраст домена, кто владелец, какие изменения вносились в регистрационные данные и т.д.
Копия памяти человека
Кто-то считает, что нужно сохранять в архиве всю
информацию, какую человек когда-либо увидел или прочитал, в том числе фотографии, видеоролики, заметки, книги, веб-страницы, статьи. Возможно, даже записи с видеорегистратора, который постоянно работает и записывает всё, что происходит вокруг. Желательно свои мысли тоже записывать (в которых есть смысл).
Такой архив — это своеобразная «цифровая память» человека, копия его жизни, всех событий и воспоминаний, с полнотекстовым поиском. Цифровая копия всего, что попадало в мозг или возникало в нём самопроизвольно. Впрочем, это уже ближе к киберпанку.
НЛО прилетело и оставило здесь промокоды для читателей нашего блога:
- 15% на все тарифы VDS (кроме тарифа Прогрев) — HABRFIRSTVDS
. - — 20% на выделенные серверы AMD Ryzen и Intel Core — HABRFIRSTDEDIC
.
Доступно до 31 декабря 2022 г.
Сохраненная копия страницы в поисковых системах Яндекс и Google
Для сохранения копий страниц понадобятся дополнительные сервисы. Поисковые системы сохраняют последние версии страниц, которые были проиндексированы поисковым роботом.
Для этого в строке поиска Яндекс вводим адрес сайта с оператором site: или url: в зависимости от того, что хотим проверить конкретную страницу или ресурс целиком. Нажимаем на стрелочку рядом с URL и выбираем «Сохраненная копия».
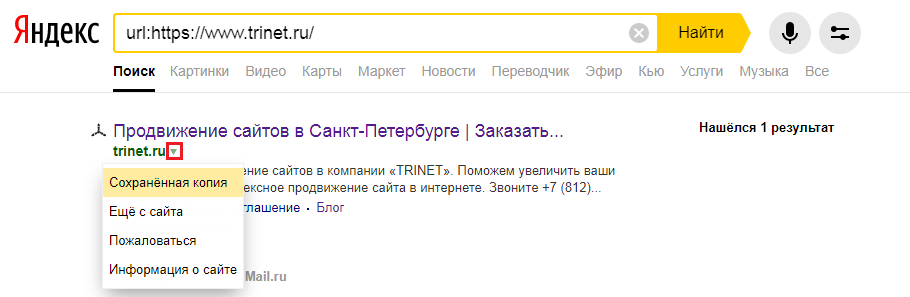
Откроется последняя версия страницы, которая есть у ПС. Можно посмотреть только текст, выбрав одноименную вкладку.
Посмотреть сохраненную копию конкретной страницы в Google можно с помощью оператора cache. Например, вводим cache:trinet.ru и получаем:
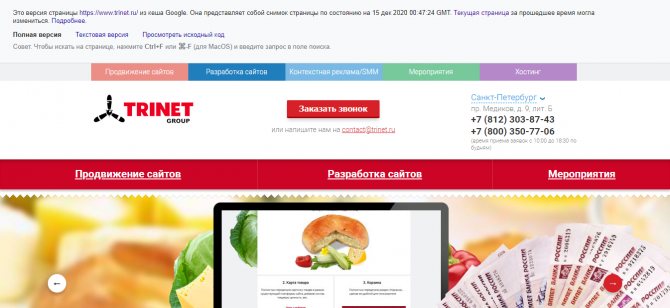
Вы так же можете посмотреть текстовую версию страницы.
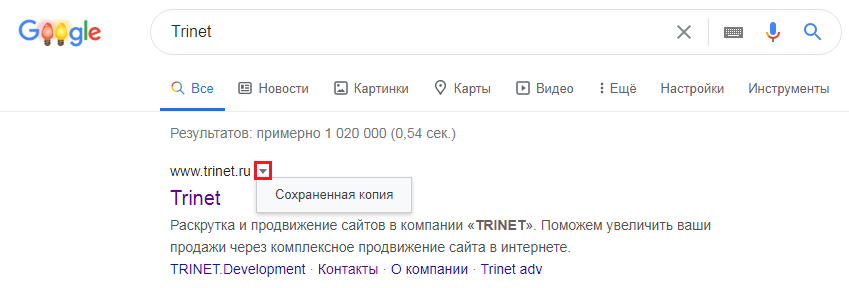
Найти сохраненную версию страницы можно и через выдачу Google. Необходимо:
- использовать оператор site:, либо указать сразу необходимый URL
- найти страницу в выдаче
- нажать на стрелочку рядом с URL
- выбрать «Сохраненная копия»
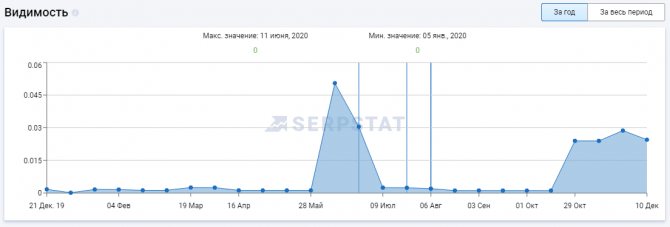
Платформа Serpstat
С помощью этого инструмента можно посмотреть изменения видимости сайта в поисковой выдаче за год или за все время, что сайт находится в базе Serpstat.
Сервис Keys.so
Используя этот сервис можно посмотреть, сколько страниц находится в выдаче, в ТОП – 1, ТОП – 3 и т.д. Можно регулировать параметры на графике и выгружать полную статистику в Excel.
Накопители
На чём хранить личный архив? Теоретически можно сбрасывать архив на компакт-диски или магнитную ленту. Но с ними возникнет проблема поиска в реальном времени. Ведь это основная функция информационного архива — выдавать информацию мгновенно по запросу. Так что самым реалистичным вариантом видится информационное хранилище на HDD (с резервированием по типу RAID).
Многое зависит от объёмов архива. Если у вас скачаны все голливудские фильмы за последние 50 лет в разрешении 4K, то не остаётся вариантов, кроме магнитной ленты. Современные картриджи формата LTO-9 объёмом 45 терабайт стоят не очень дорого.

Как восстановить сайт из архива
Часто нужно не только посмотреть, как менялись страницы в прошлом, но и скачать содержимое сайта. Это легко сделать с помощью автоматических сервисов.
О самых популярных расскажем ниже.
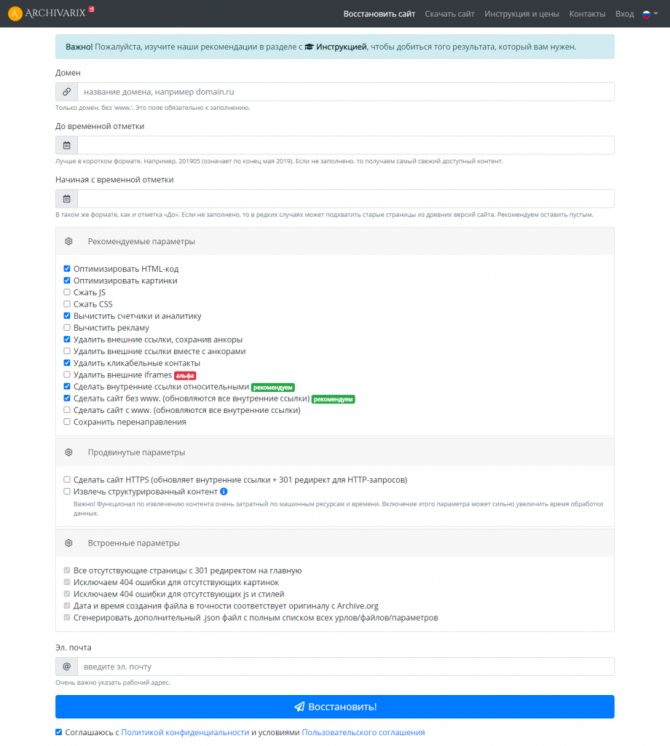
Сервис Архиварикс
Сервис может восстановить как рабочие, так и не рабочие сайты. Недоступные ресурсы он скачивает из Веб-архива. Для этого нужно заполнить данные на странице https://archivarix.com/ru/restore/ и нажать кнопку «Восстановить».
Для работы с полученными файлами Архиварикс предоставляет собственную систему CMS, которая совместима с любыми другими системами.
Сервис Rush Analytics
Данный сервис также восстанавливает сайты из Веб-архива. Можно задать нужную дату скачивания для любой страницы. На выходе получаем html-документ со всеми стилями, картинками и т.д.
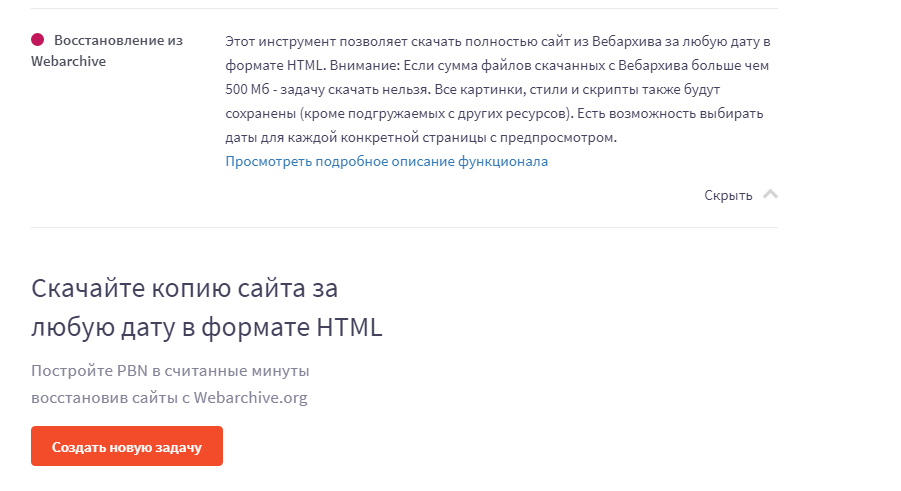
Ссылка на сервис https://www.rush-analytics.ru/land/skachivanie-kopiy-saytov-iz-wayback-machine
Сервис R-tools.org
Еще один сервис, который позволяет скачивать сайты из Веб-архива. Можно скачать сайт целиком, можно отдельные страницы. Оплата происходит только за то, что скачено, поэтому выгоднее использовать данный сервис только для небольших сайтов.
Сервис Wayback Machine Download (waybackmachinedownloader.com)
С помощью него можно скачивать данные из Веб-архива. Есть демо-версия. Подходит для больших проектов. Единственный минус – сервис не русифицирован.
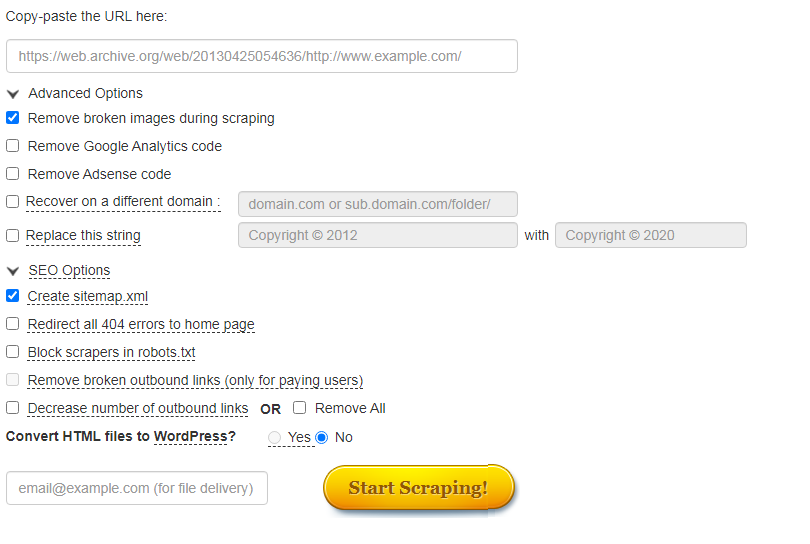
Сервис Mydrop.io
Этот сервис помогает найти уже освободившиеся или скоро освобождающиеся интересные домены по вашим параметрам.
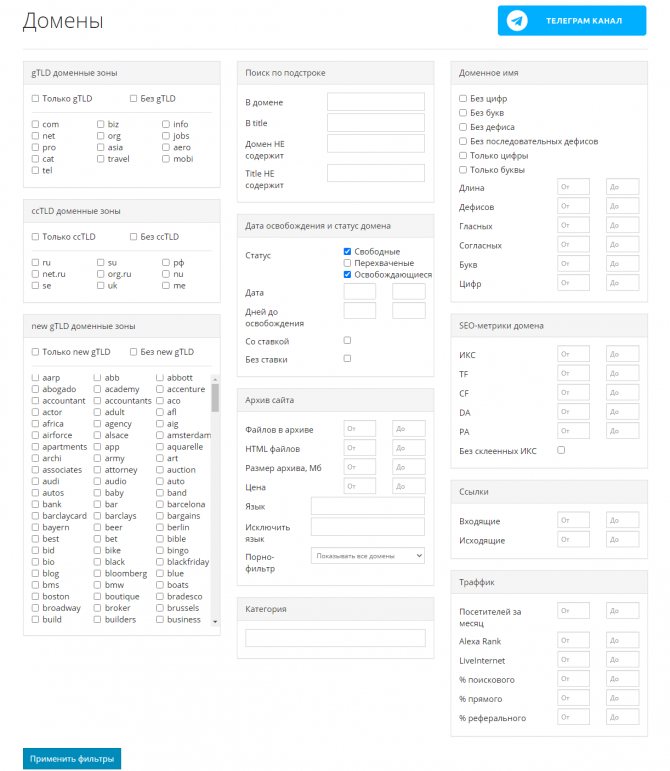
Для этого необходимо применить заданные фильтры, после чего можно скачать контент этих сайтов. Сервис делает скриншоты сайтов до их удаления. Перед скачиванием можно предварительно посмотреть содержимое ресурса. Особенностью является то, что данные выгружаются не из ВебАрхива, а из собственной базы.
Что важно учесть при резервном копировании
Во время копирования сайт может работать немного медленнее — не стоит заниматься этим в пик посещаемости.
По FTP чаще всего происходит заражение сайта — работайте в FTP-клиенте на защищённом от вирусов компьютере.
Подготовьте место для бэкапа файлов и дампа базы данных сайта — на компьютере, удалённом FTP-cервере или облачном хранилище (Dropbox, Google Drive, Облако Mail.ru и другие). Весить они будут почти столько же, сколько сам сайт (чуть меньше, но всё же).
Кэш браузера, когда ничего не помогает
Страницу целиком таким образом не посмотришь, но картинки и скрипты с некоторых сайтов определенное время хранятся на вашем компьютере. Их можно использовать для поиска информации. К примеру, по картинке из инструкции можно найти аналогичную на другом сайте. Кратко о подходе к просмотру файлов кэша в разных браузерах:
Safari
Ищем файлы в папке ~/Library/Caches/Safari.
Google Chrome
В адресной строке набираем chrome://cache
Opera
В адресной строке набираем opera://cache
Mozilla Firefox
Набираем в адресной строке about:cache и находим на ней путь к каталогу с файлами кеша.
mydrop.io
(реф. ссылка)
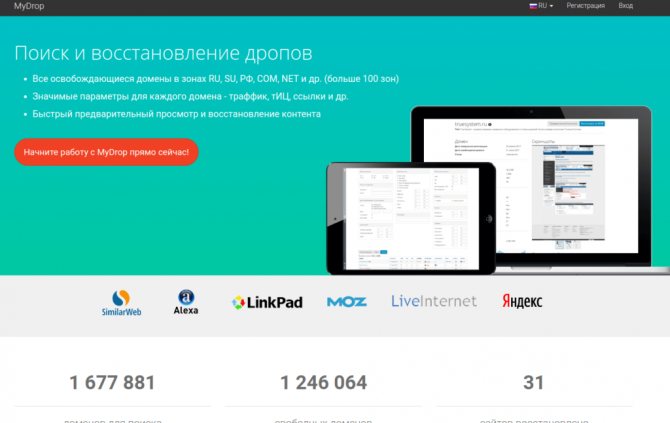
Удобный сервис, кроме фнкционала восстановления контента сайта имеет фунционал поиска доменов по различным параметрам. Пользуюсь им больше года.
Из преимуществ:
- широкий набор фильтров для поиска домена
- возможность подписки на фильтр
- информативная таблица доменов с полезными seo метрикам( TF, CF, DA, PA, LinkPad, SimilarWeb, LiveInternet, Alexa)
- показывают кол-во файлов, которые восстановить и размер в МБ
- показывают, есть ли ставки на домен через сервис expired.ru
- Есть своя Cms
- адекватные цены
- скидки при пополнении счета от 3000 руб.
- интерфейс на русском
Из минусов:
- нет пробного периода либо бесплатного восстановления, если восстонавливаемый сайт «небольшой»
- есть функционал предварительного просмотра, но он очень сыроват и на счета должна быть сумма не меньше чем стоимость восстановления